The Stuff About Deepseek You Probably Hadn't Thought-about. And Actual…
페이지 정보
작성자 Malorie 작성일25-01-31 09:38 조회4회 댓글0건관련링크
본문
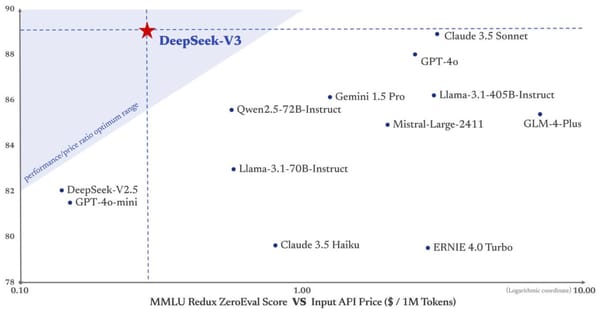 Curious about what makes DeepSeek so irresistible? DeepSeek is the name of the Chinese startup that created the DeepSeek-V3 and DeepSeek-R1 LLMs, which was founded in May 2023 by Liang Wenfeng, an influential figure within the hedge fund and AI industries. Deepseek Coder, an improve? Given the immediate and response, it produces a reward decided by the reward model and ends the episode. Starting from the SFT model with the final unembedding layer removed, we skilled a mannequin to absorb a immediate and response, and output a scalar reward The underlying goal is to get a mannequin or system that takes in a sequence of text, and returns a scalar reward which ought to numerically symbolize the human desire. The reward operate is a combination of the choice mannequin and a constraint on coverage shift." Concatenated with the unique prompt, that text is handed to the choice mannequin, which returns a scalar notion of "preferability", rθ. The worth perform is initialized from the RM.
Curious about what makes DeepSeek so irresistible? DeepSeek is the name of the Chinese startup that created the DeepSeek-V3 and DeepSeek-R1 LLMs, which was founded in May 2023 by Liang Wenfeng, an influential figure within the hedge fund and AI industries. Deepseek Coder, an improve? Given the immediate and response, it produces a reward decided by the reward model and ends the episode. Starting from the SFT model with the final unembedding layer removed, we skilled a mannequin to absorb a immediate and response, and output a scalar reward The underlying goal is to get a mannequin or system that takes in a sequence of text, and returns a scalar reward which ought to numerically symbolize the human desire. The reward operate is a combination of the choice mannequin and a constraint on coverage shift." Concatenated with the unique prompt, that text is handed to the choice mannequin, which returns a scalar notion of "preferability", rθ. The worth perform is initialized from the RM.
Then the expert models have been RL utilizing an unspecified reward perform. Parse Dependency between information, then arrange recordsdata in order that ensures context of every file is earlier than the code of the current file. Finally, the replace rule is the parameter update from PPO that maximizes the reward metrics in the current batch of data (PPO is on-coverage, which implies the parameters are only up to date with the current batch of immediate-technology pairs). Instead of simply passing in the present file, the dependent files within repository are parsed. To evaluate the generalization capabilities of Mistral 7B, we high quality-tuned it on instruction datasets publicly accessible on the Hugging Face repository. The ethos of the Hermes series of fashions is focused on aligning LLMs to the consumer, with highly effective steering capabilities and management given to the end person. Shortly after, DeepSeek-Coder-V2-0724 was launched, featuring improved common capabilities via alignment optimization. This normal method works because underlying LLMs have received sufficiently good that when you adopt a "trust but verify" framing you may let them generate a bunch of synthetic information and just implement an approach to periodically validate what they do. Synthesize 200K non-reasoning data (writing, factual QA, self-cognition, translation) utilizing DeepSeek-V3. Medium Tasks (Data Extraction, Summarizing Documents, Writing emails..
Writing and Reasoning: Corresponding improvements have been noticed in inner check datasets. In the event you don’t believe me, simply take a learn of some experiences humans have enjoying the game: "By the time I end exploring the extent to my satisfaction, I’m level 3. I have two food rations, a pancake, and a newt corpse in my backpack for food, deepseek and I’ve discovered three more potions of various colours, all of them still unidentified. That night, he checked on the nice-tuning job and browse samples from the mannequin. "We estimate that in comparison with the perfect international requirements, even the perfect home efforts face a few twofold gap by way of mannequin construction and training dynamics," Wenfeng says. The KL divergence term penalizes the RL policy from moving substantially away from the initial pretrained model with each training batch, which will be useful to make sure the mannequin outputs fairly coherent textual content snippets. More information: DeepSeek-V2: A robust, Economical, and Efficient Mixture-of-Experts Language Model (DeepSeek, GitHub). Something to notice, is that after I present more longer contexts, the model seems to make a lot more errors. Each model in the collection has been skilled from scratch on 2 trillion tokens sourced from 87 programming languages, making certain a complete understanding of coding languages and syntax.
This commentary leads us to imagine that the strategy of first crafting detailed code descriptions assists the model in additional effectively understanding and addressing the intricacies of logic and dependencies in coding duties, notably those of upper complexity. Before we venture into our analysis of coding environment friendly LLMs. Why this issues - text games are exhausting to study and will require wealthy conceptual representations: Go and play a text adventure game and discover your own expertise - you’re both studying the gameworld and ruleset while additionally building a rich cognitive map of the environment implied by the textual content and the visible representations. The raters had been tasked with recognizing the true recreation (see Figure 14 in Appendix A.6). Reproducible directions are within the appendix. These GPTQ fashions are recognized to work in the next inference servers/webuis. Comparing different models on similar workouts. We call the resulting fashions InstructGPT. InstructGPT nonetheless makes easy mistakes. Note that tokens outside the sliding window still affect subsequent word prediction.
댓글목록
등록된 댓글이 없습니다.