Detailed Notes on Deepseek In Step by Step Order
페이지 정보
작성자 Josie 작성일25-02-07 10:18 조회6회 댓글0건관련링크
본문
In response to DeepSeek’s inner benchmark testing, DeepSeek V3 outperforms each downloadable, "openly" obtainable fashions and "closed" AI models that may only be accessed by means of an API. When using DeepSeek-R1 mannequin with the Bedrock’s playground or InvokeModel API, please use DeepSeek’s chat template for optimal outcomes. Say all I want to do is take what’s open source and perhaps tweak it a bit of bit for my specific agency, or use case, or language, or what have you. What are the psychological fashions or frameworks you employ to assume about the gap between what’s obtainable in open source plus fine-tuning versus what the leading labs produce? What is driving that hole and the way may you anticipate that to play out over time? The closed models are effectively forward of the open-supply fashions and the gap is widening. I don’t assume this system works very properly - I tried all of the prompts within the paper on Claude 3 Opus and none of them labored, which backs up the concept the bigger and smarter your mannequin, the extra resilient it’ll be. The paper says that they tried making use of it to smaller fashions and it did not work practically as effectively, so "base models had been unhealthy then" is a plausible explanation, however it's clearly not true - GPT-4-base is probably a usually higher (if costlier) mannequin than 4o, which o1 is based on (could be distillation from a secret larger one although); and LLaMA-3.1-405B used a somewhat comparable postttraining process and is about nearly as good a base mannequin, however is not competitive with o1 or R1.
 Just through that pure attrition - folks go away all the time, whether it’s by choice or not by choice, and then they discuss. If the export controls find yourself taking part in out the way in which that the Biden administration hopes they do, then chances are you'll channel a whole country and multiple huge billion-dollar startups and firms into going down these growth paths. But the way the United States ought to pursue that objective is hotly contested. 0.001 for the primary 14.3T tokens, and to 0.0 for the remaining 500B tokens. However, in periods of speedy innovation being first mover is a entice creating costs which might be dramatically greater and decreasing ROI dramatically. The corporate's first mannequin was launched in November 2023. The corporate has iterated multiple instances on its core LLM and has constructed out a number of completely different variations. How does the data of what the frontier labs are doing - even though they’re not publishing - find yourself leaking out into the broader ether? Given the issue issue (comparable to AMC12 and AIME exams) and the special format (integer solutions solely), we used a mix of AMC, AIME, and Odyssey-Math as our problem set, removing multiple-choice options and filtering out problems with non-integer solutions.
Just through that pure attrition - folks go away all the time, whether it’s by choice or not by choice, and then they discuss. If the export controls find yourself taking part in out the way in which that the Biden administration hopes they do, then chances are you'll channel a whole country and multiple huge billion-dollar startups and firms into going down these growth paths. But the way the United States ought to pursue that objective is hotly contested. 0.001 for the primary 14.3T tokens, and to 0.0 for the remaining 500B tokens. However, in periods of speedy innovation being first mover is a entice creating costs which might be dramatically greater and decreasing ROI dramatically. The corporate's first mannequin was launched in November 2023. The corporate has iterated multiple instances on its core LLM and has constructed out a number of completely different variations. How does the data of what the frontier labs are doing - even though they’re not publishing - find yourself leaking out into the broader ether? Given the issue issue (comparable to AMC12 and AIME exams) and the special format (integer solutions solely), we used a mix of AMC, AIME, and Odyssey-Math as our problem set, removing multiple-choice options and filtering out problems with non-integer solutions.
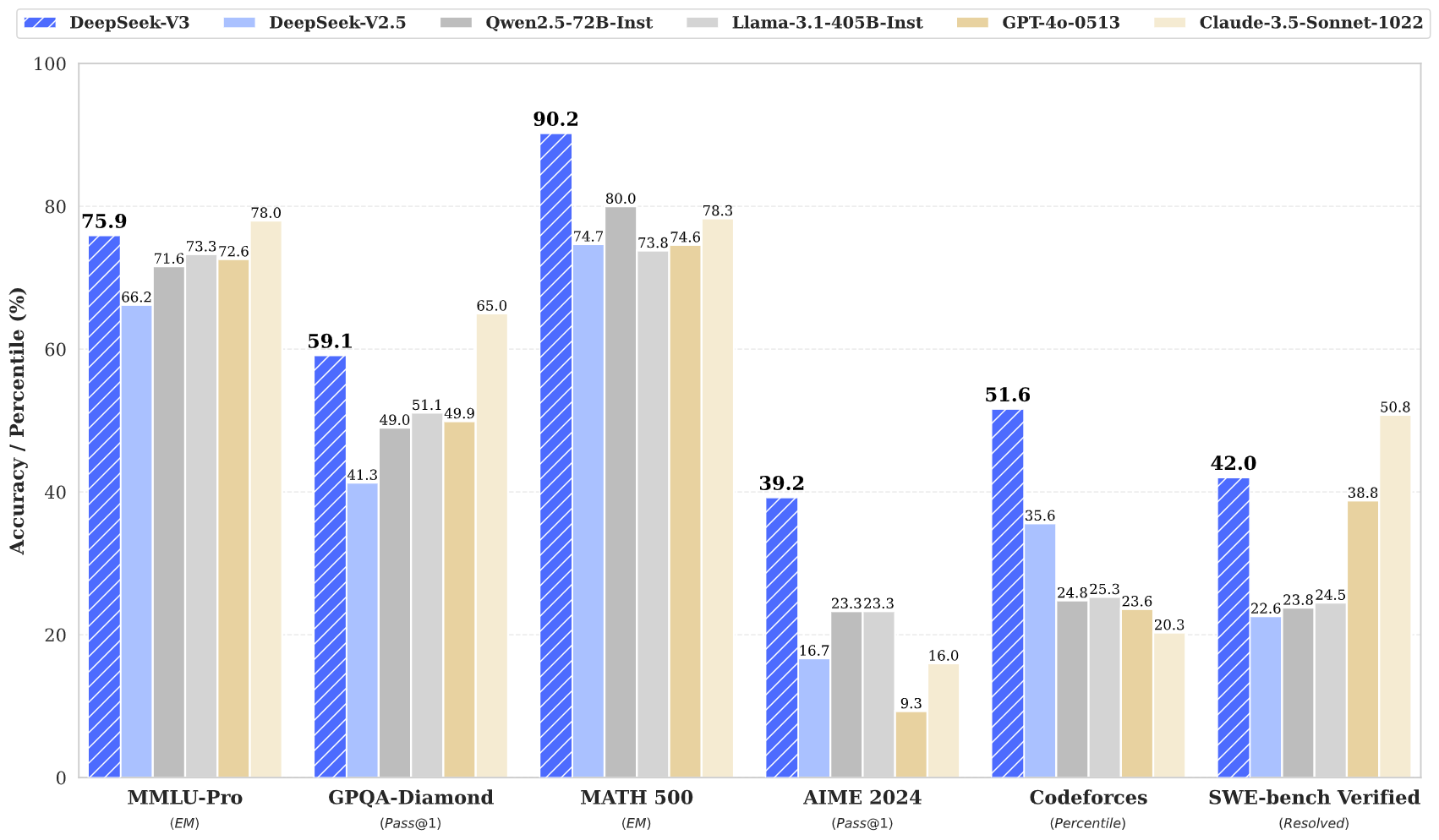 I do not know how you can work with pure absolutists, who consider they're particular, that the foundations mustn't apply to them, and continually cry ‘you are trying to ban OSS’ when the OSS in question shouldn't be only being focused but being given multiple actively pricey exceptions to the proposed rules that would apply to others, normally when the proposed rules would not even apply to them. Now you don’t have to spend the $20 million of GPU compute to do it. In information science, tokens are used to characterize bits of uncooked information - 1 million tokens is equal to about 750,000 phrases. DeepSeek was capable of train the mannequin using an information center of Nvidia H800 GPUs in simply round two months - GPUs that Chinese firms have been not too long ago restricted by the U.S. • At an economical price of only 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at the moment strongest open-source base mannequin. That is an approximation, as deepseek coder permits 16K tokens, and approximate that every token is 1.5 tokens. For reference, this degree of functionality is alleged to require clusters of closer to 16K GPUs, the ones being…
I do not know how you can work with pure absolutists, who consider they're particular, that the foundations mustn't apply to them, and continually cry ‘you are trying to ban OSS’ when the OSS in question shouldn't be only being focused but being given multiple actively pricey exceptions to the proposed rules that would apply to others, normally when the proposed rules would not even apply to them. Now you don’t have to spend the $20 million of GPU compute to do it. In information science, tokens are used to characterize bits of uncooked information - 1 million tokens is equal to about 750,000 phrases. DeepSeek was capable of train the mannequin using an information center of Nvidia H800 GPUs in simply round two months - GPUs that Chinese firms have been not too long ago restricted by the U.S. • At an economical price of only 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at the moment strongest open-source base mannequin. That is an approximation, as deepseek coder permits 16K tokens, and approximate that every token is 1.5 tokens. For reference, this degree of functionality is alleged to require clusters of closer to 16K GPUs, the ones being…
The open-supply world, to this point, has more been concerning the "GPU poors." So in case you don’t have quite a lot of GPUs, however you still want to get business value from AI, how are you able to try this? We have now some rumors and hints as to the architecture, simply because people speak. They only did a reasonably big one in January, where some people left. OpenAI does layoffs. I don’t know if people know that. We don’t know the scale of GPT-four even as we speak. The sad thing is as time passes we know less and less about what the big labs are doing because they don’t tell us, in any respect. How labs are managing the cultural shift from quasi-academic outfits to firms that need to show a revenue. You want quite a lot of everything. During usage, it's possible you'll need to pay the API service provider, consult with DeepSeek's relevant pricing insurance policies. An unoptimized version of DeepSeek AI V3 would need a financial institution of high-finish GPUs to reply questions at reasonable speeds. Retrying a few occasions results in robotically producing a better reply. I retried a couple more instances. Usually Deepseek is more dignified than this.
If you cherished this short article and you would like to get extra info about شات DeepSeek kindly check out our own web site.
댓글목록
등록된 댓글이 없습니다.