Deepseek Chatgpt? It is Easy For those who Do It Smart
페이지 정보
작성자 Jodie 작성일25-02-10 05:20 조회8회 댓글0건관련링크
본문
 But is the essential assumption right here even true? In 2025 it looks like reasoning is heading that means (although it doesn’t have to). I’ll revisit this in 2025 with reasoning models. I shifted the gathering of links at the tip of posts to (what ought to be) month-to-month roundups of open models and worthwhile hyperlinks. Tencent is one among China’s largest tech corporations and the proprietor of WeChat, the tremendous app that has 1.3 billion month-to-month customers. China’s progress in AI ought to proceed to be carefully watched, particularly as the brand new administration’s strategy to China comes into view. Unlike OpenAI and Meta, which practice fashions on monumental clusters of chopping-edge GPUs, DeepSeek has optimised its approach. This seemingly innocuous mistake could be proof - a smoking gun per se - that, sure, DeepSeek was educated on OpenAI models, as has been claimed by OpenAI, and that when pushed, it'll dive again into that coaching to speak its fact. DeepSeek has also launched DeepSeek Coder-V2, which offers even higher performance and effectivity in comparison with the unique DeepSeek Coder.
But is the essential assumption right here even true? In 2025 it looks like reasoning is heading that means (although it doesn’t have to). I’ll revisit this in 2025 with reasoning models. I shifted the gathering of links at the tip of posts to (what ought to be) month-to-month roundups of open models and worthwhile hyperlinks. Tencent is one among China’s largest tech corporations and the proprietor of WeChat, the tremendous app that has 1.3 billion month-to-month customers. China’s progress in AI ought to proceed to be carefully watched, particularly as the brand new administration’s strategy to China comes into view. Unlike OpenAI and Meta, which practice fashions on monumental clusters of chopping-edge GPUs, DeepSeek has optimised its approach. This seemingly innocuous mistake could be proof - a smoking gun per se - that, sure, DeepSeek was educated on OpenAI models, as has been claimed by OpenAI, and that when pushed, it'll dive again into that coaching to speak its fact. DeepSeek has also launched DeepSeek Coder-V2, which offers even higher performance and effectivity in comparison with the unique DeepSeek Coder.
Even in the course of the July interview (before V3’s release), DeepSeek’s CEO Liang Wenfeng mentioned many Westerners are (shall be) simply shocked to see innovation stem from a Chinese company and at ghast seeing Chinese companies stepping up as innovators fairly than merely followers. There are a variety of Washington DC eyes on China and its news cycle, but few cowl its know-how and AI community nicely. Across expertise broadly, AI was still the most important story of the yr, as it was for 2022 and 2023 as properly. 2023 was the formation of latest powers within AI, instructed by the GPT-four release, dramatic fundraising, acquisitions, mergers, and launches of numerous projects that are nonetheless closely used. I’m going to largely bracket the question of whether the DeepSeek models are nearly as good as their western counterparts. DeepSeek was developed by a team of Chinese researchers to advertise open-source AI. Investors questioned the US artificial intelligence boom after the Chinese tool appeared to supply a comparable service to ChatGPT with far fewer assets. Similar instances have been observed with different models, like Gemini-Pro, which has claimed to be Baidu's Wenxin when asked in Chinese.
 Despite its capabilities, customers have observed an odd habits: DeepSeek-V3 typically claims to be ChatGPT. Are DeepSeek-V3 and DeepSeek-V1 actually cheaper, more environment friendly peers of GPT-4o, Sonnet and o1? Much of the content overlaps considerably with the RLFH tag covering all of put up-coaching, but new paradigms are starting in the AI area. I’ve included commentary on some posts the place the titles don't fully seize the content. 14 posts). Post-training is now seen because the region the place frontier laboratories are scaling compute the fastest. 10 posts). These case studies (and playing with the fashions) are instrumental to a grounded understanding of AI’s progress. Some of my favourite posts are marked with ★. 9 posts). At the best level, my read of the situation remains that the advantages of extra openness (relative to the established order) outweigh the risks, so clearly articulating why and interfacing with policymakers is a core mode of the blog and my profession. This allows anybody to view its code, design paperwork, use it’s code or even modify it freely. So positive, if DeepSeek heralds a brand new era of a lot leaner LLMs, it’s not great news in the short term if you’re a shareholder in Nvidia, Microsoft, Meta or Google.6 But if DeepSeek is the big breakthrough it seems, it simply became even cheaper to prepare and use probably the most subtle models people have to this point constructed, by a number of orders of magnitude.
Despite its capabilities, customers have observed an odd habits: DeepSeek-V3 typically claims to be ChatGPT. Are DeepSeek-V3 and DeepSeek-V1 actually cheaper, more environment friendly peers of GPT-4o, Sonnet and o1? Much of the content overlaps considerably with the RLFH tag covering all of put up-coaching, but new paradigms are starting in the AI area. I’ve included commentary on some posts the place the titles don't fully seize the content. 14 posts). Post-training is now seen because the region the place frontier laboratories are scaling compute the fastest. 10 posts). These case studies (and playing with the fashions) are instrumental to a grounded understanding of AI’s progress. Some of my favourite posts are marked with ★. 9 posts). At the best level, my read of the situation remains that the advantages of extra openness (relative to the established order) outweigh the risks, so clearly articulating why and interfacing with policymakers is a core mode of the blog and my profession. This allows anybody to view its code, design paperwork, use it’s code or even modify it freely. So positive, if DeepSeek heralds a brand new era of a lot leaner LLMs, it’s not great news in the short term if you’re a shareholder in Nvidia, Microsoft, Meta or Google.6 But if DeepSeek is the big breakthrough it seems, it simply became even cheaper to prepare and use probably the most subtle models people have to this point constructed, by a number of orders of magnitude.
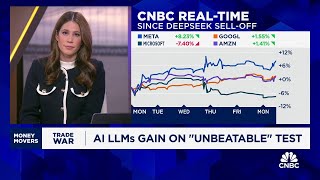
Apple actually closed up yesterday, as a result of DeepSeek is good news for the corporate - it’s proof that the "Apple Intelligence" wager, that we are able to run adequate native AI fashions on our telephones could actually work someday. I’m sure AI individuals will discover this offensively over-simplified but I’m trying to maintain this comprehensible to my mind, not to mention any readers who do not need stupid jobs the place they can justify studying blogposts about AI all day. And, you recognize, we’ve had a bit of bit of the cadence over the last couple of weeks of - I feel this week it’s a rule or two a day associated to some vital issues around artificial intelligence and our ability to protect the nation in opposition to our adversaries. ★ Tülu 3: The next period in open post-coaching - a mirrored image on the past two years of alignment language models with open recipes. ★ Switched to Claude 3.5 - a enjoyable piece integrating how careful put up-training and product decisions intertwine to have a substantial affect on the usage of AI.
For more regarding ديب سيك شات take a look at the web page.
댓글목록
등록된 댓글이 없습니다.